
type
status
date
slug
summary
category
tags
icon
password
AI 摘要
在这个
AI技术不断进步的时代,智能软件正逐渐成为我们生活和工作中不可或缺的一部分。它们不仅极大地提高了效率,还为我们带来了前所未有的便利。
今天,我将向大家推荐三款具有突破性功能的智能软件
它们分别是
Ollama Ollama WebUI以及Ollama中文网精选模型。1. Ollama:本地部署大模型的实践
前排介绍
Ollama是一个开源项目,致力于简化大型语言模型(LLM)的本地部署过程。它允许用户在自己的硬件上运行和测试最新的语言模型,无需依赖云服务。
Ollama和Ollama WebUI简介
Ollama提供了一个类似于OpenAI的API接口,使得开发者可以轻松地在自己的应用程序中集成大型语言模型。此外,Ollama WebUI为用户提供了一个友好的界面,用于管理和与模型进行交互。
Ollama模型硬件要求
运行Ollama模型需要一定的硬件资源。例如,运行7B型号的模型至少需要8 GB的RAM,而更大的模型如33B则需要32 GB的RAM。这些要求确保了模型能够顺畅运行,提供稳定的服务。
使用教程
Windows命令行(CMD)输出下面代码会自动跳转浏览器进行下载
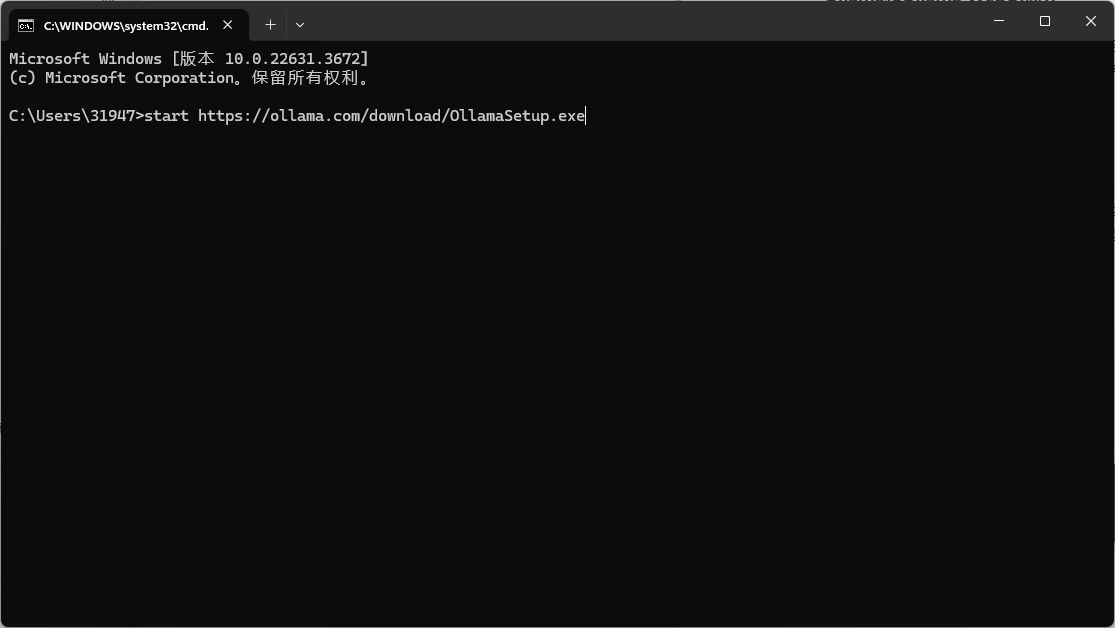
下载完成后双击安装即可如果没有图标的可以进行搜索
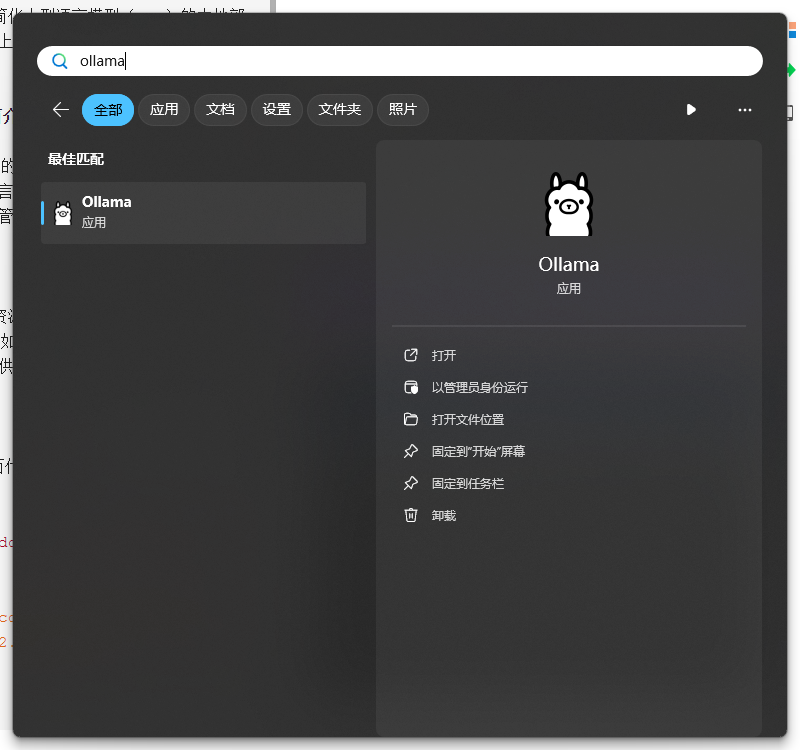
打开后我们再次使用命令行工具(CMD)输入命令查看版本ollama -v再输入ollama换出页面菜单
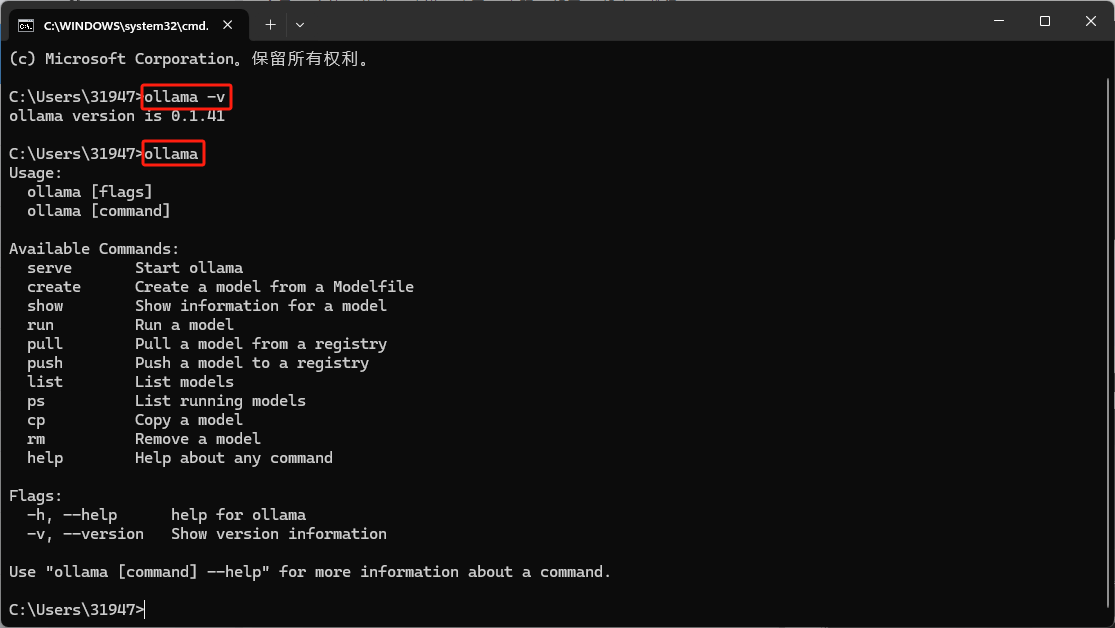
下面我给出详细的菜单介绍
OK上面的详细注释想必大家都能看懂了接下来我们来安装模型这里我推荐中文模型阿里云的qwen配置差一点的用0.5B、1.8B、2B、4B配置牛逼的有4090的建议上32B左右的模型下面我放出目前已经支持的显卡类型
系列 | 卡片及加速器 |
AMD Radeon RX | 7900 XTX 7900 XT 7900 GRE 7800 XT 7700 XT 7600 XT 7600 6950 XT 6900 XTX 6900XT 6800 XT 6800 Vega 64 Vega 56 |
AMD Radeon PRO | W7900 W7800 W7700 W7600 W7500 W6900X W6800X Duo W6800X W6800 V620 V420 V340 V320 Vega II Duo Vega II VII SSG |
AMD Instinct | MI300X MI300A MI300 MI250X MI250 MI210 MI200 MI100 MI60 MI50 |
计算能力 | 系列 | 卡片及加速器 |
9.0 | NVIDIA | H100 |
8.9 | GeForce RTX 40xx | RTX 4090 RTX 4080 RTX 4070 Ti RTX 4060 Ti |
NVIDIA 专业版 | L4 L40 RTX 6000 | |
8.6 | GeForce RTX 30xx | RTX 3090 Ti RTX 3090 RTX 3080 Ti RTX 3080 RTX 3070 Ti RTX 3070 RTX 3060 Ti RTX 3060 |
NVIDIA 专业版 | A40 RTX A6000 RTX A5000 RTX A4000 RTX A3000 RTX A2000 A10 A16 A2 | |
8.0 | NVIDIA | A100 A30 |
7.5 | GeForce GTX/RTX | GTX 1650 Ti TITAN RTX RTX 2080 Ti RTX 2080 RTX 2070 RTX 2060 |
NVIDIA 专业版 | T4 RTX 5000 RTX 4000 RTX 3000 T2000 T1200 T1000 T600 T500 | |
Quadro | RTX 8000 RTX 6000 RTX 5000 RTX 4000 | |
7.0 | NVIDIA | TITAN V V100 Quadro GV100 |
6.1 | NVIDIA TITAN | TITAN Xp TITAN X |
GeForce GTX | - | GTX 1080 Ti GTX 1080 GTX 1070 Ti GTX 1070 GTX 1060 GTX 1050 |
Quadro | - | P6000 P5200 P4200 P3200 P5000 P4000 P3000 P2200 P2000 P1000 P620 P600 P500 P520 |
Tesla | - | P40 P4 |
6.0 | NVIDIA | Tesla P100 Quadro GP100 |
5.2 | GeForce GTX | GTX TITAN X GTX 980 Ti GTX 980 GTX 970 GTX 960 GTX 950 |
Quadro | - | M6000 24GB M6000 M5000 M5500M M4000 M2200 M2000 M620 |
Tesla | - | M60 M40 |
5.0 | GeForce GTX | GTX 750 Ti GTX 750 NVS 810 |
Quadro | - | K2200 K1200 K620 M1200 M520 M5000M M4000M M3000M M2000M M1000M K620M M600M M500M |
安装ollama模型并且启用
首先我们前往ollamamodes页面
地址
https://ollama.com/library当然也可以输入命令进入
找到
qwen模型,点击进入选择和自己电脑配置吃得消的模型
点击右上角的复制按钮
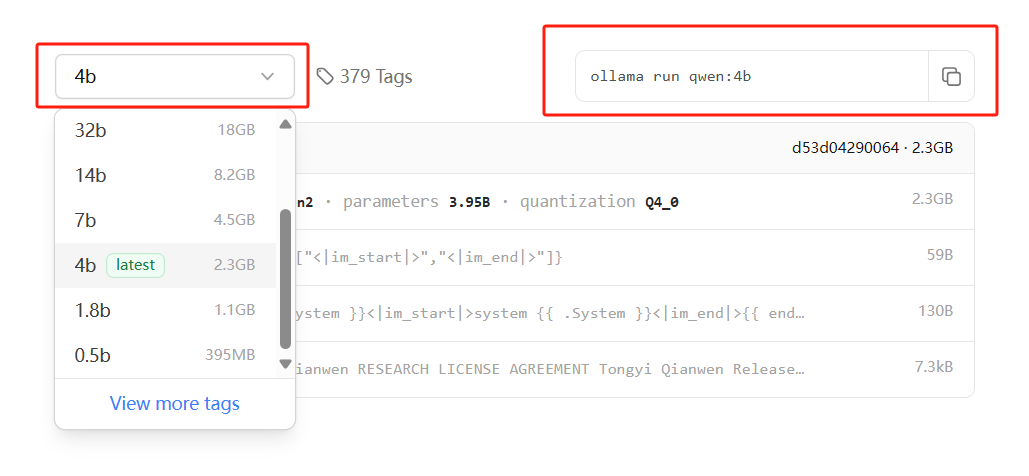
到CMD窗口右击粘贴回车即可自动下载安装
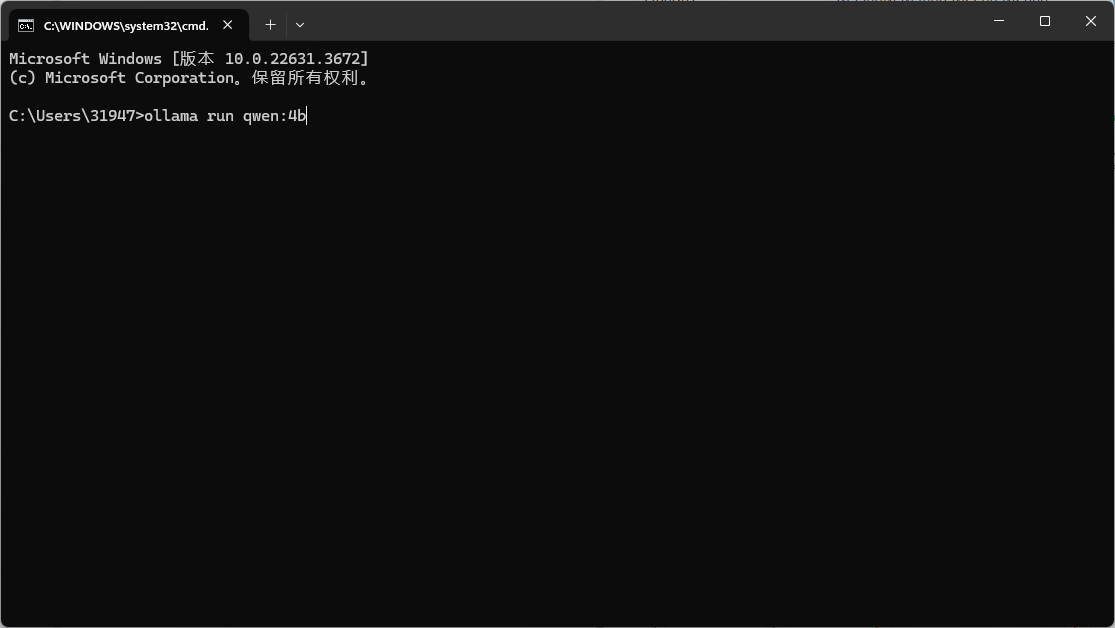
这个时候我们需要确保网络质量良好带宽的速率最起码100~300MB的带宽
然后在命令行窗口进行对话即可

对话计算的数独取决于你的CPU,如果有GPU的话速度会快一些
但是这样的对话方式是不是不太美观?接下来教大家搭建Ollama WebUI
Ollama WebUI部署
Ollama WebUI为用户提供了一个图形界面,用于下载模型和与模型进行对话。用户可以通过WebUI选择模型,下载并刷新页面以开始交互
安装方式
必要的条件
本地已经安装了
ollama 和docker并且开启了wsl和虚拟化操作
- 第一步开启windwos必要的环境

打开控制面板选择程序
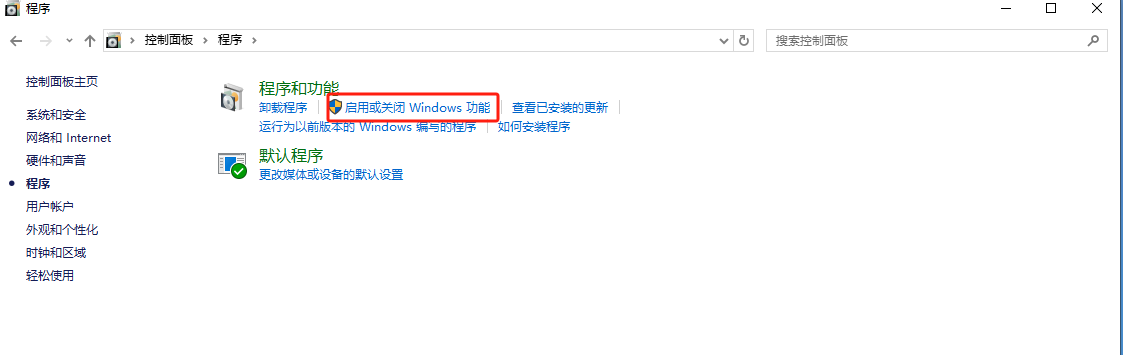
点击红色部分
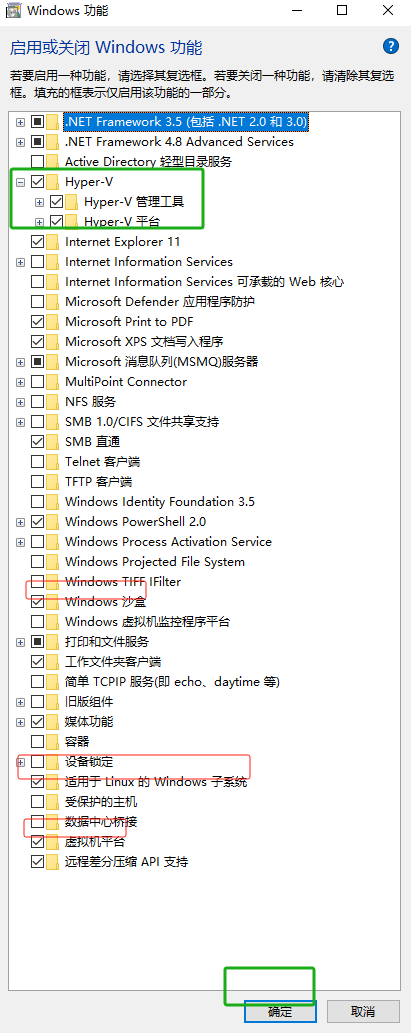
开启红色框选的部分点击确定然后重启
- 第二步安装docker
前往docker官方下载安装
如果官网进不去我们提供下载
后台回复:
docker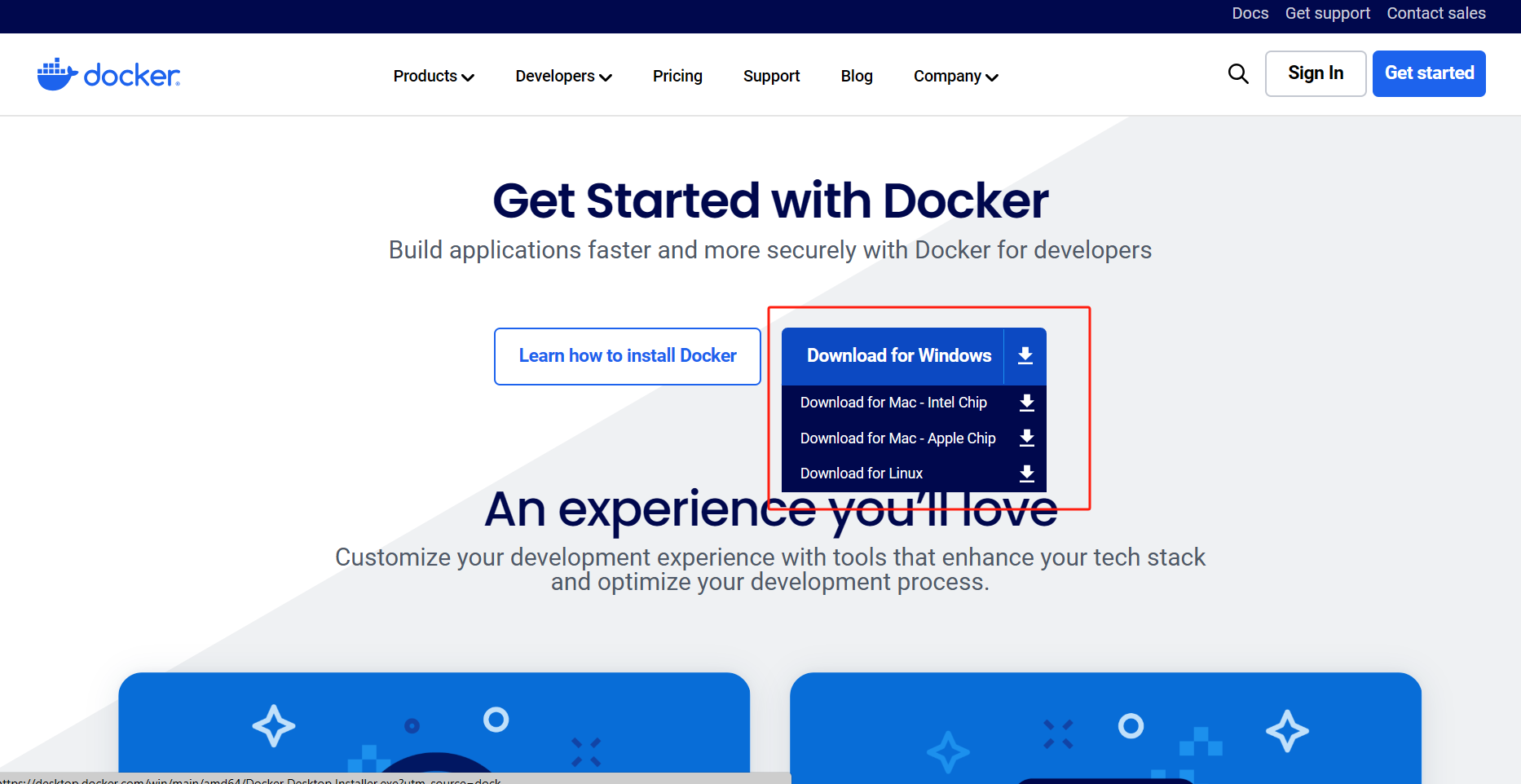
网址:https://www.docker.com/get-started/
下载完毕后双击打开一路安装即可
接下来开始安装Ollama WebUI
下面是详细的方式
windwos只用CPU运行的选择第一个
选择GPU运行的选择第三个
下面的命令在cmd窗口粘贴即可运行
注意!使用下面的命令需要您的docker正常运行打开软件左下角显示绿色即可
- 如果 Ollama 在您的计算机上,请使用以下命令:
- 如果 Ollama 位于其他服务器上, 请使用以下命令:
要连接到另一台服务器上的 Ollama
请将更改为服务器的 URL:
OLLAMA_BASE_URL- 要运行支持 Nvidia GPU 的 Open WebUI, 请使用以下命令:
- 仅供 OpenAI API 使用的安装
- 如果您仅使用 OpenAI API, 请使用以下命令:
安装带有捆绑 Ollama 支持的 Open WebUI
此安装方法使用将 Open WebUI 与 Ollama 捆绑在一起的单个容器映像,允许通过单个命令简化设置。根据硬件设置选择适当的命令:
- 支持 GPU: 通过运行以下命令来利用 GPU 资源:
- 仅适用于 CPU: 如果您不使用 GPU,请改用以下命令:
这两个命令都有助于 Open WebUI 和 Ollama 的内置、轻松安装,确保您可以快速启动和运行所有内容。
安装完成后,您可以在
http://localhost:3000访问
Open WebUI。享受!😄安装完毕后双击打开docker可以看见如下左下角运行状态Containers页面有您已经部署好的项目鼠标点击3000:8080
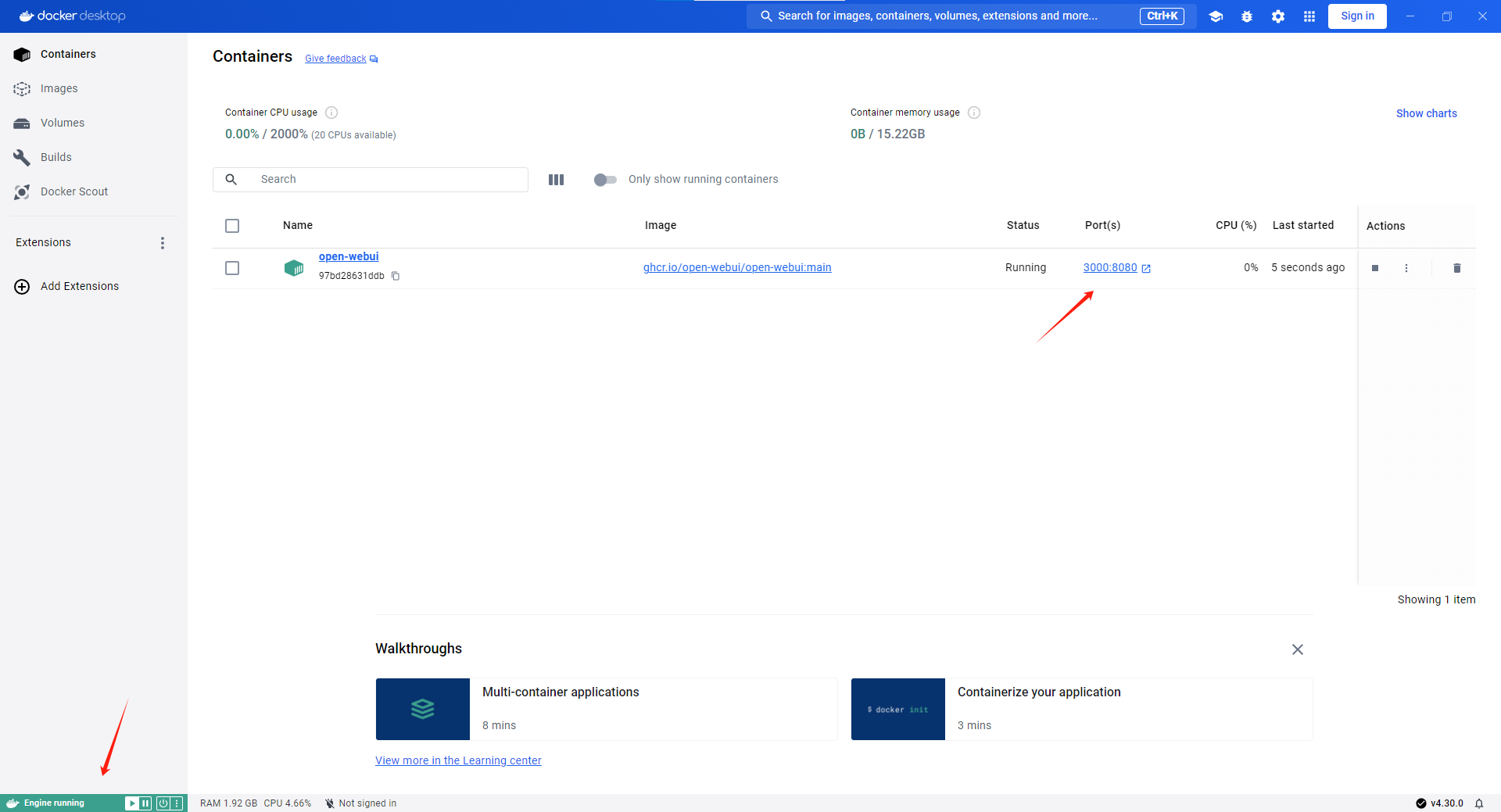
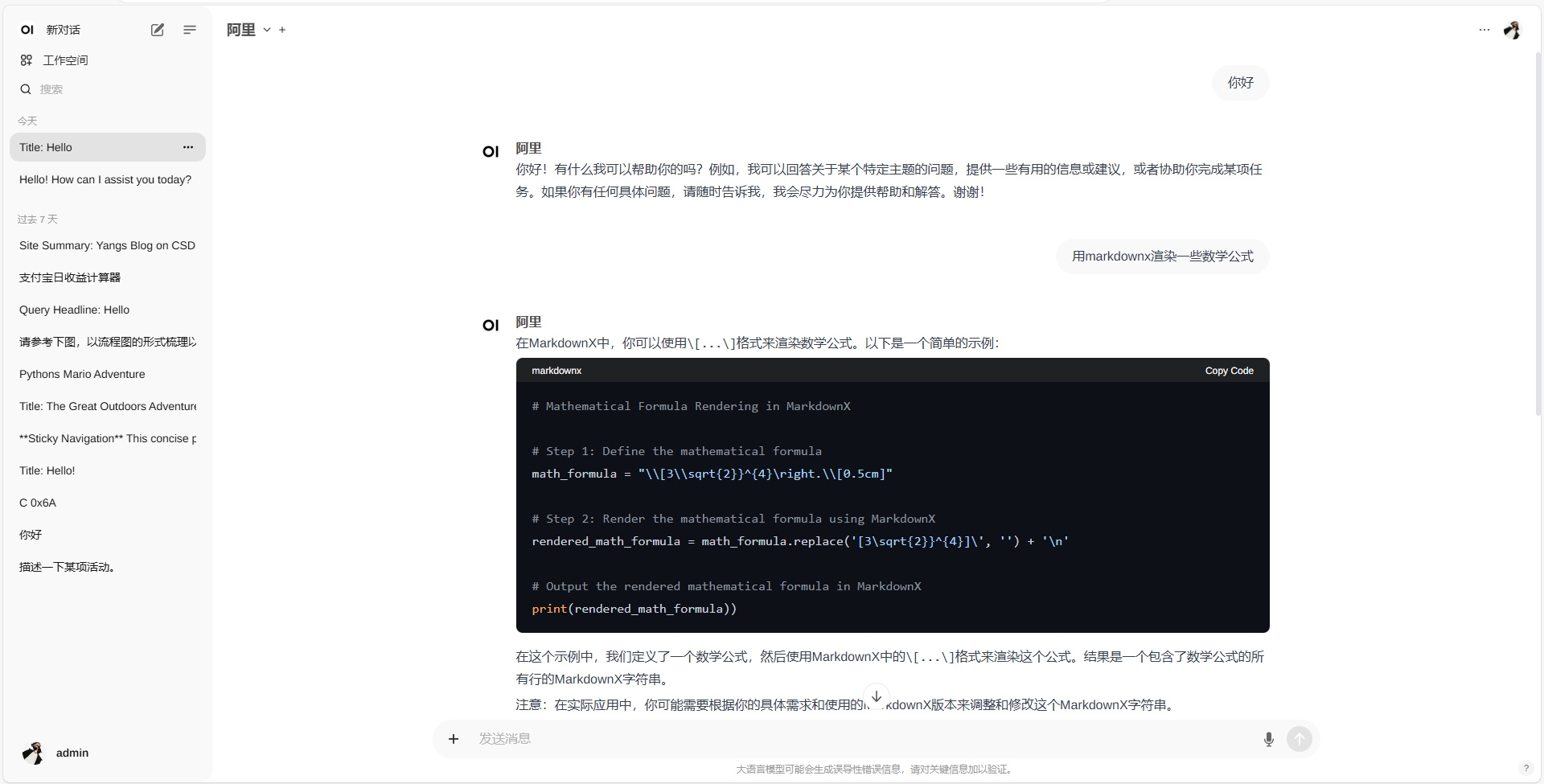
我们进入映射的端口3000:800然后进行注册账号,一定要注册账号因为首次注册账号的是管理员确认身份的然后就可以愉快的对话选择模型了
Ollama中文网
这个是对中文的小伙伴很友好的
内容基本都是中文,模型介绍也很清楚
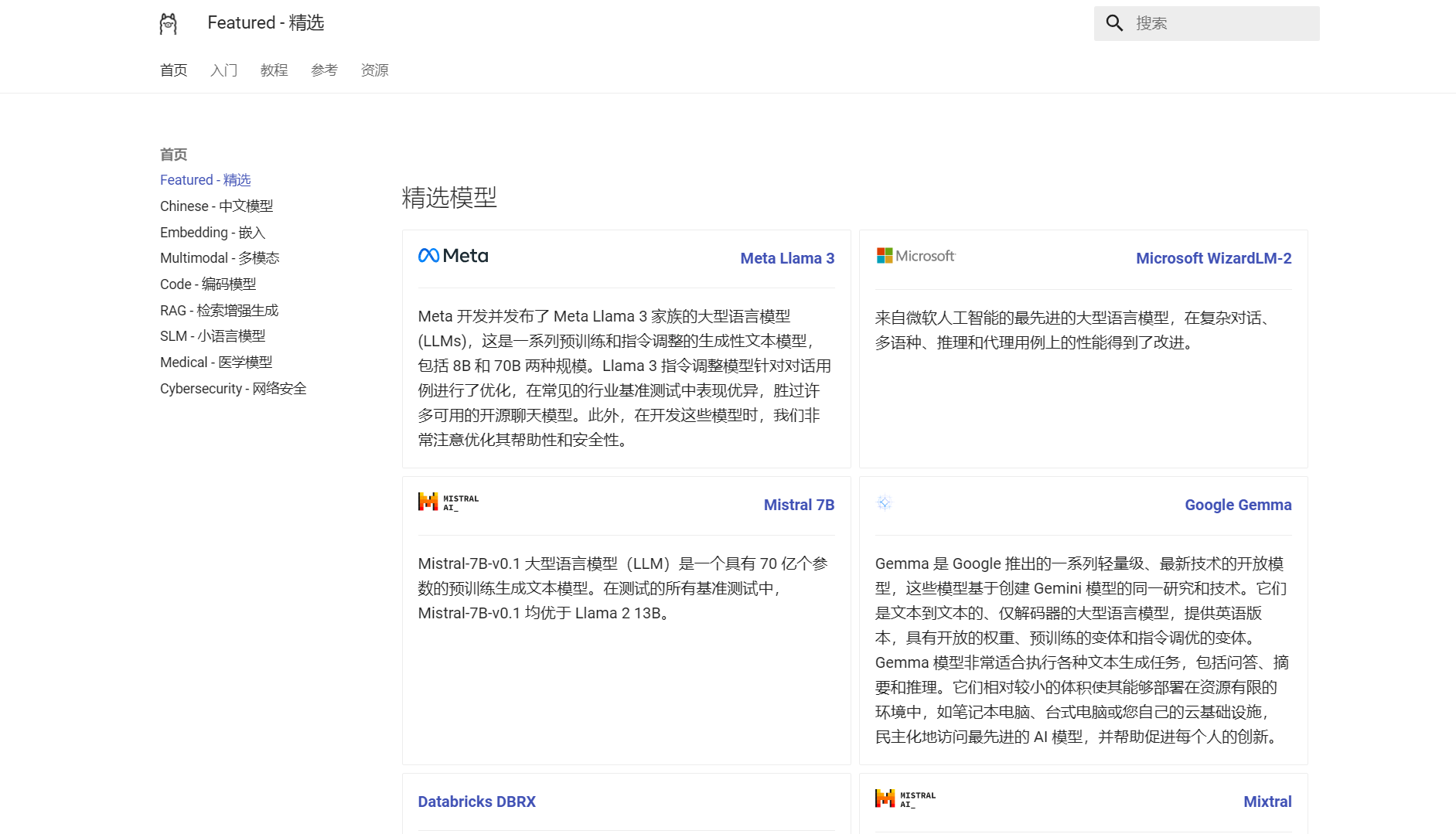
推荐网址:https://ollama.fan
- 作者:Yong Liu
- 链接:https://ikiss.eu.org/article/abc/6
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章